
In non-market valuation we typically deal with survey data. In essence, we conduct survey experiments where we vary experimentally one or more key variables, such as cost, to understand its effect on individual choices. What we are interested in is in calculating the effect of theis key variable on the outcome we observe, which we usually hope to be statistically significant.
One of the major steps of designing a survey deals with deciding the sample size. Ideally we want to have as many observations as possible to ensure we can identify this effect. But there may be financial constraints that guide the sample size decision. How many observations are needed at a minimum to actually find this effect we are interested in? Is there a mechanism to understand what our sampling effort should be?
The answer is yes: do a power calculation. This is perhaps an important step that should go with designing a new survey that is not always performed. This is the first of a series of posts showing the usefulness of power calculations in several environmental economics applications. In this post, I will first focus on performing power calculations when our dependent variable is continuous.
Attenuating Hypothetical Bias
I will use as an example a study to understand the impact of cheap talk scripts in contingent valuation outcomes. Martinsson and Carlsson (2006) test whether a cheap talk script affects estimated willingness to pay (WTP) by asking an open-ended WTP question.
Before answer the WTP question, respondents are presented with a cheap talk script. A possible formulation of a cheap talk script is as follows: “Do not forget that this money will be drawn from your household’s budget! You will therefore have less money at the end of the month for consumption and savings” (Ami et al., 2011). The intention of a cheap talk script is to remind respondents of any financial constraints and avoid yay-saying. Thus, it should reduce the hypothetical bias present.
It is expected that a cheap talk script will decrease stated WTP. However, Martinsson and Carlsson (2006) find that instead their cheap talk script decreased the proportion of respondents with a negative WTP, but had no statistical effect on stated WTP.
To analyze the effect of a cheap talk script on stated behavior, a group of respondents (control group) is not shown the cheap talk script, while the other (treatment group) is. In essence, the information treatment in their survey experiment is the cheap talk script. Randomization is at individual level and there seem to be no differences in terms of observable characteristics in the control and treatment groups.
Power Calculations
Perhaps the most popular motivation for power calculations is to determine ex-ante the necessary sample size to identify a given effect (Duflo et al., 2007). Given a significance level, typically denoted by , an expected effect size, and a given power, one can determine the necessary sample size to test the hypothesis in question. These four parameters are a function of one another: one can determine one out of this four parameters, so long as the remaining three are specified.
In Martinsson and Carlsson (2006), the survey data has already been collected, so the sample size is pre-determined. Instead of trying to find what would have been the optimal sample size, it is more useful to perform the calculation to infer on the power of the experiment (Cohen, 2013, p. 27). Does Martinsson and Carlsson (2006) have enough power in their experiment to identify the effect of a cheap talk script? Before performing the necessary power calculations, I will go through each of the four parameters required for power calculations.
Martinsson and Carlsson (2006) report some of the inputs I need to perform the power calculations. The sample size of the control group is 500×0.47 (that is, the initial sample size times the response rate). The sample size of the treatment group is 500×0.49. The sample size is 235 for the control group and 245 for the treatment group.
The effect size is the “degree to which a phenomenon exists” (Cohen, 2013, p. 4). The effect size is a “pure number” that is free from the scale of the original measurement unit (Cohen, 2013). The WTP ellicited in the survey needs to be standardized in order to perform power calculations (Cohen, 2013, p. 11). In the case of continuous variables, standardization is possible by dividing the different between population means by the standard deviation, that is:


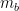
> (85.4-72.5)/184.1 [1] 0.07007061
According to Duflo et al. (2007), the power of a design is “the probability that, for a given size and a given statistical significance level, we will be able to reject the hypothesis of zero effect”. If the goal of the researcher is to estimate the needed sample size, significance level or minimum detectable effect size, one would set power at 80% by convention (Duflo et al., 2007). Instead, my aim is to estimate the power of this experiment.
The significance level is set at 5% across all power calculations, which is the convention in most peer-reviewed papers (Duflo et al., 2007). The power calculations are conducted using the pwr package in R (Champely et al., 2018).
library(pwr)
I now set my parameters. I have two sub-samples with an unequal number of observations (n1= 235, n2= 245).
n1=235 n2=245
The effect size of the cheap talk script seems to be in the order of 0.07, which I use as an input to perform the power calculation:
> pwr.2p2n.test(h=0.07, n1=n1, n2=n2, sig.level = 0.05, power = NULL,
alternative = c("greater"))
difference of proportion power calculation for binomial distribution (arcsine transformation)
h = 0.07
n1 = 235
n2 = 245
sig.level = 0.05
power = 0.1899153
alternative = greater
NOTE: different sample sizes
The power of this experiment is only 19%. A power of 19 % means that I have an 19 % chance of finding the effect size of 0.07. This is a very low power, comparing with the conventional power level of 80%.
Instead, I recognize that 0.07 is but an estimate of the effect size given this particular sample. Let us assume that the desired effect size is in the order of 0.2, which Cohen (2013) considers to be a “small” effect size.
These are the resulting power calculations:
> pwr.2p2n.test(h=0.2, n1=n1, n2=n2, sig.level = 0.05, power = NULL,
alternative = c("greater"))
difference of proportion power calculation for binomial distribution (arcsine transformation)
h = 0.2
n1 = 235
n2 = 245
sig.level = 0.05
power = 0.7073162
alternative = greater
NOTE: different sample sizes
The power of the experiment has increased substantially (71%), but still lower than the conventional 80%.
If power is low, i.e. the “a priori probability of rejecting the null hypothesis was low” (Cohen, 2013, p. 4), hence the conclusions drawn from interpreting statistically insignificant parameters should be regarded as ambiguous. Low power estimates imply that I am very unlikely to reject the null hypothesis of statistical insignificance of the cheap talk variable. Failure to reject the null is very likely to be due to the lack of power rather than the true effect being zero. Indeed, Martinsson and Carlsson (2006) find that the coefficient associated with their cheap talk dummy is statistically insignificant in their OLS regression.
If the null hypothesis of statistically insignificance is indeed true, then inference from OLS is correct. However, if the null hypothesis is not true, which is my expectation from economic theory, then I am incurring in a Type II error, since I fail to reject statistically insignificance.
References
Ami, D., Aprahamian, F., Chanel, O., & Luchini, S. (2011). A test of cheap talk in different hypothetical contexts: The case of air pollution. Environmental and resource economics, 50(1), 111.
Champely, S., Ekstrom, C., Dalgaard, P., Gill, J., Weibelzahl, S., Anandkumar, A., Ford, C., Volcic, R., De Rosario, H., De Rosario, M.H., 2018. Package ‘pwr.’ R Package Version 1–2.
Cohen, J., 2013. Statistical power analysis for the behavioral sciences. Routledge.
Duflo, E., Glennerster, R., Kremer, M., 2007. Using Randomization in Development Economics Research: A Toolkit (Discussion Paper Series No. 6059).
Martinsson, P., & Carlsson, F. (2006). Do experience and cheap talk influence willingness to pay in an open-ended contingent valuation survey?. rapport nr.: Working Papers in Economics, (190).

2 Comments